Jiaming Han
Biography
I am a third-year PhD student of MMLab@CUHK advised by Prof. Xiangyu Yue. Before that, I received my Master and Bachelor degree from Wuhan University and Central South University, respectively. I also interned at Bytedance Seed, Shanghai AI Lab and Tencent YouTu Lab.
I have board interest in computer vision, natural language processing and deep learning. Recently, I focus on the unification of vision and language in one autoregressive model, such as multimodal LLMs, unified multimodal models and autoregressive generative models.
I expect to graduate in Summer 2027 and am actively seeking full-time job opportunities. Feel free to contact me via Email and Wechat.
Selected Publications

BitDance: Scaling Autoregressive Generative Models with Binary Tokens

UniWeTok: An Unified Binary Tokenizer with Codebook Size 2128 for
Unified Multimodal Large Language Model

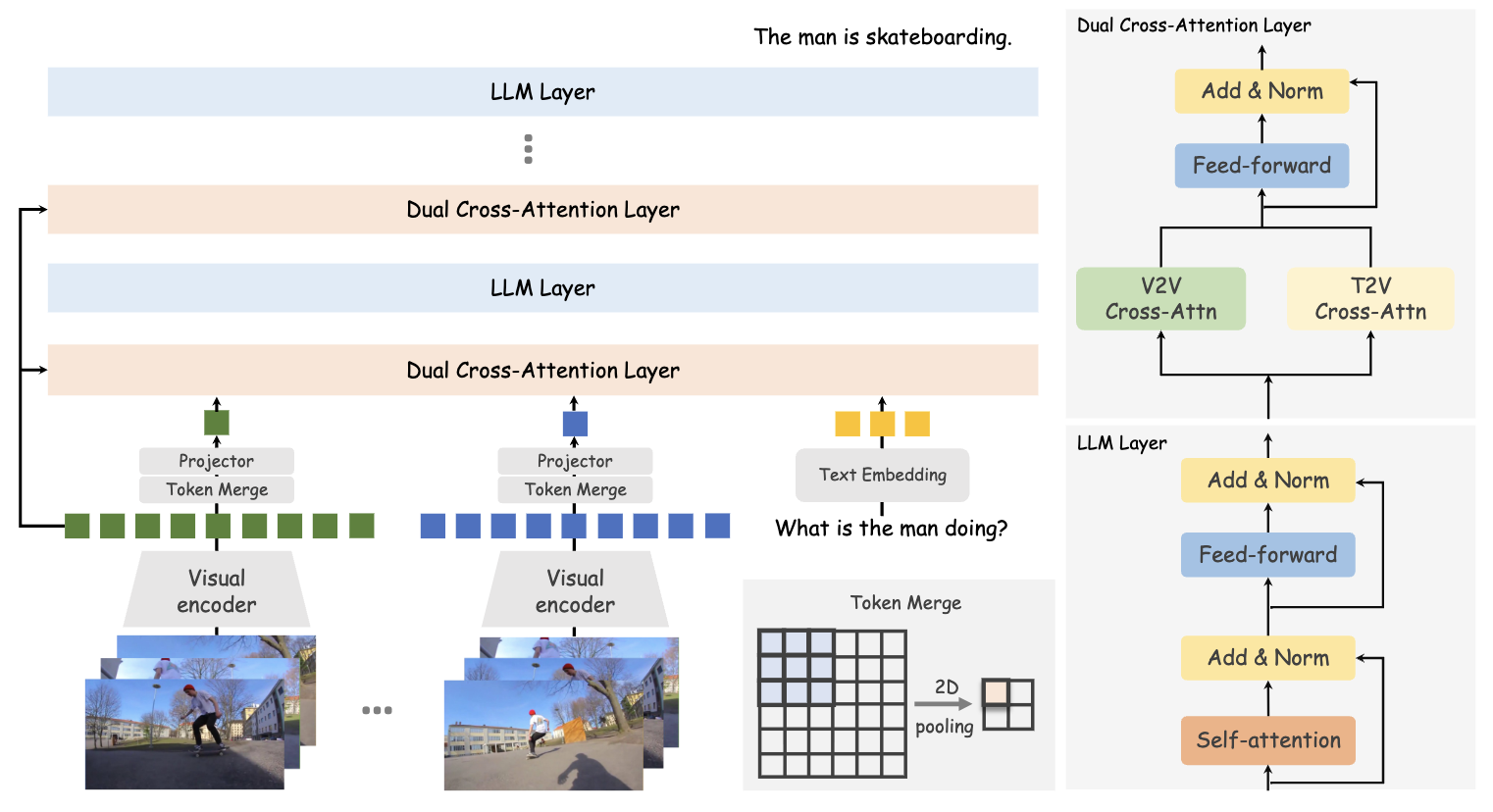
Bridge: Growing Visual Generative Capacity for Pre-Trained MLLMs
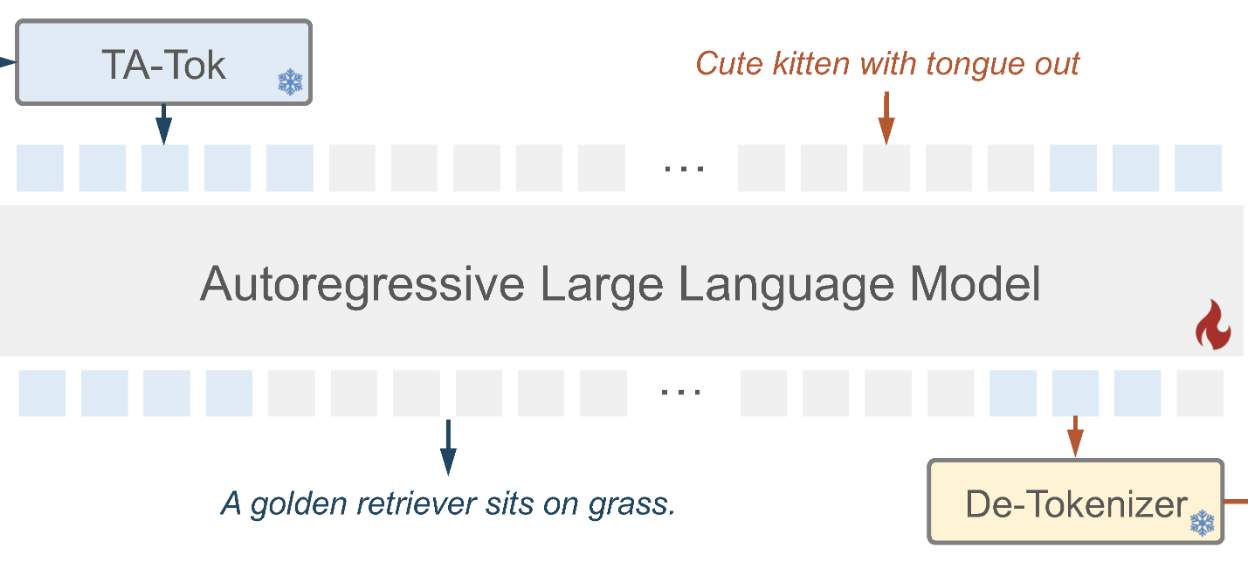
Vision as a Dialect: Unifying Visual Understanding and Generation via
Text-Aligned Representations
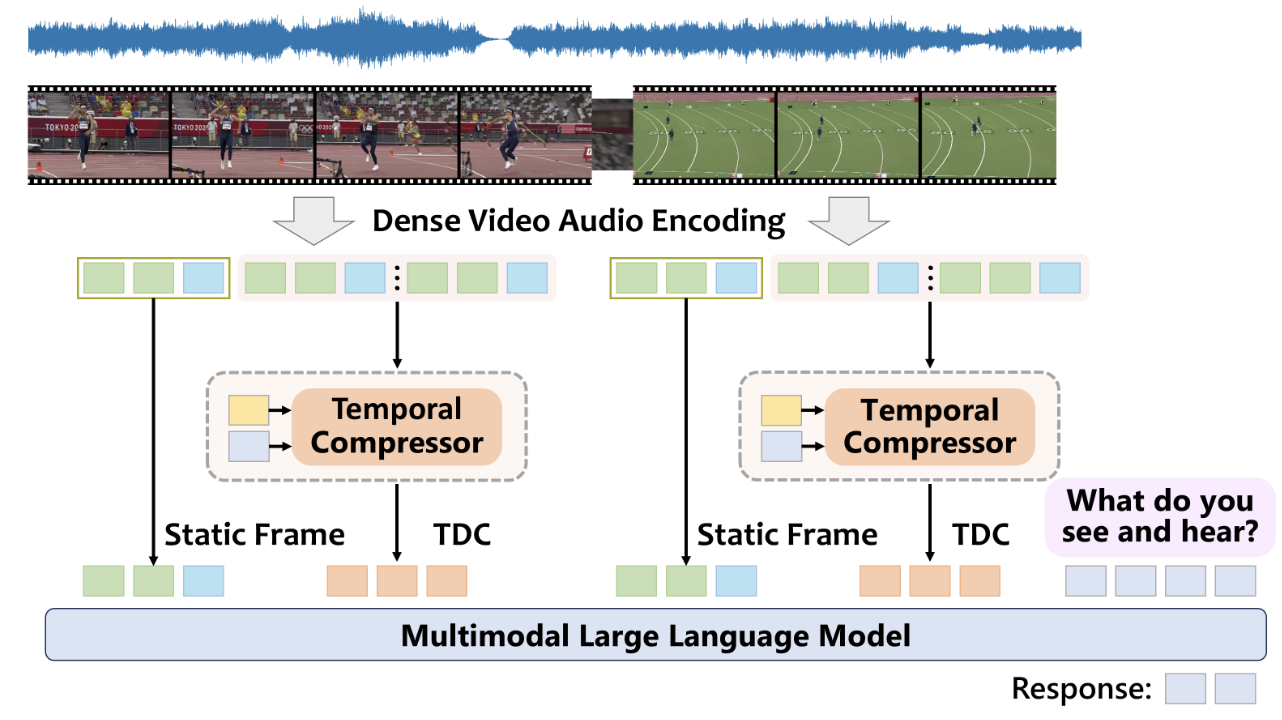
Multimodal Long Video Modeling Based on Temporal Dynamic Context
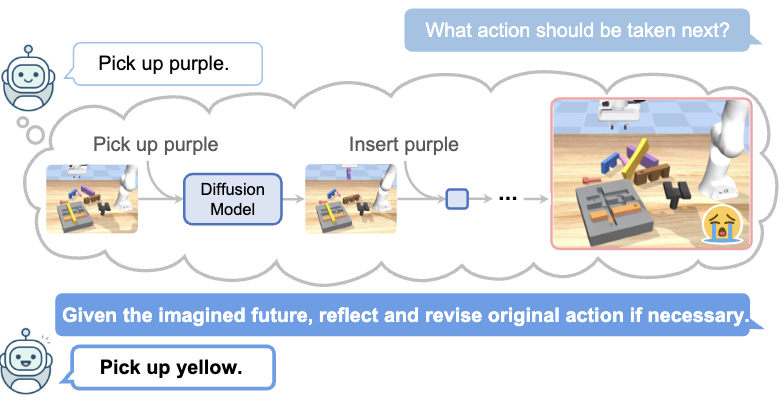
Reflective Planning: Vision-Language Models for Multi-Stage Long-Horizon
Robotic Manipulation

Retrieval-Augmented Personalization for Multimodal Large Language Models

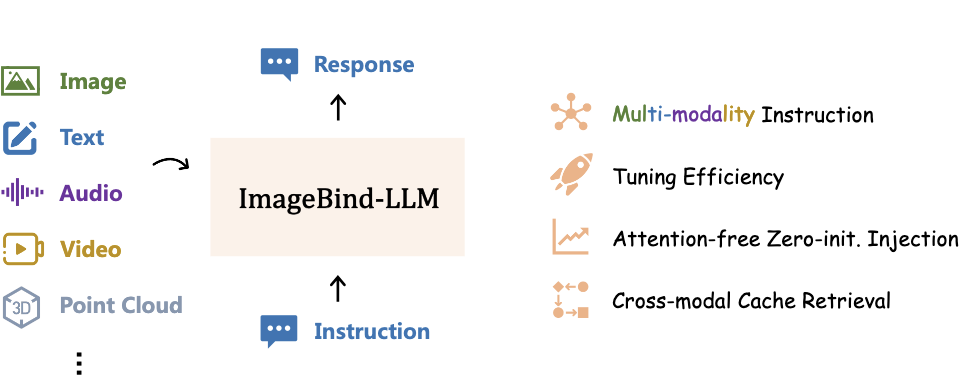
OneLLM: One Framework to Align All Modalities with Language



Experience
Educations
09/2023 - Present
PhD. The Chinese University of Hong Kong
09/2019 - 06/2022
M.E. Wuhan University
09/2015 - 06/2019
B.E. Central South University
Activities
- Reviewer of CVPR’21-24, ICCV’21-23, NIPS’23, ICLR’24, WACV’22, ECCV’22-24, AAAI’23-24
- Reviewer of TPAMI, IJCV, TIP, ISPRS, TGRS, TNNLS