Biography
I am a third-year PhD student of MMLab@CUHK advised by Prof. Xiangyu Yue. Before that, I received my Master and Bachelor degree from Wuhan University and Central South University, respectively. I also interned at Tencent Hunyuan, Bytedance Seed, Shanghai AI Lab and Tencent YouTu Lab.
My research builds toward a unified intelligent system through multimodal foundation models—from efficient multimodal alignment that binds diverse modalities to language (LLaMA-Adapter, OneLLM), to unifying multimodal understanding and generation within a single autoregressive model (Tar, BitDance), and now toward world models, with the long-term goal of building a unified large model that perceives, generates, reasons, and acts in the world.
I expect to graduate in Summer 2027 and am actively seeking full-time job opportunities. Feel free to contact me via Email and Wechat.
Selected PublicationsFull List
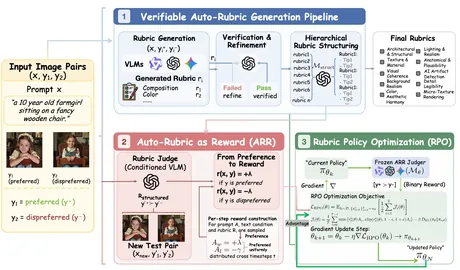
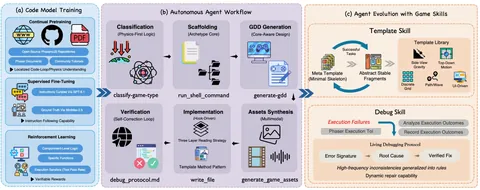
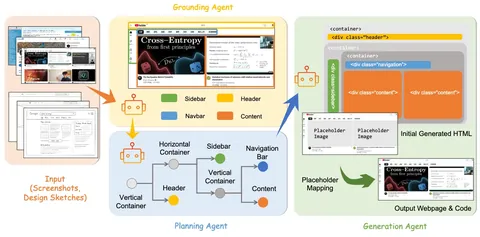




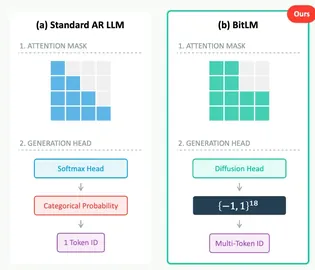












Experience
Educations
Activities
- Reviewer of CVPR’21-24, ICCV’21-23, NIPS’23, ICLR’24, WACV’22, ECCV’22-24, AAAI’23-24
- Reviewer of TPAMI, IJCV, TIP, ISPRS, TGRS, TNNLS